

Introduction #
This article mainly aims to sort out the essential difference between value and pointer passing in the Go language. Here, I would like to share a quote from William Kennedy as a summary:
Value semantics keep values on the stack, which reduces pressure on the Garbage Collector (GC). However, value semantics require various copies of any given value to be stored, tracked and maintained. Pointer semantics place values on the heap, which can put pressure on the GC. However, pointer semantics are efficient because only one value needs to be stored, tracked and maintained.
The general idea is that in Golang, value objects are stored in stack memory, and pointer objects are stored in heap memory. Therefore, using value objects can reduce the pressure on the GC. However, the efficiency of pointer passing lies in the fact that only one value needs to be passed during storage, tracking and maintenance.
Based on the above understanding, let’s try the following example
Structure definition #
The following simple struct is used as an example
type S struct {
a, b, c int64
d, e, f string
g, h, i float64
}
We will separately construct the methods for initializing value objects and pointer objects
go
func byValue() S {
return S{
a: math.MinInt64, b: math.MinInt64, c: math.MinInt64,
d: "foo", e: "foo", f: "foo",
g: math.MaxFloat64, h: math.MaxFloat64, i: math.MaxFloat64,
}
}
func byPoint() *S {
return &S{
a: math.MinInt64, b: math.MinInt64, c: math.MinInt64,
d: "foo", e: "foo", f: "foo",
g: math.MaxFloat64, h: math.MaxFloat64, i: math.MaxFloat64,
}
}
Object passing #
Memory address #
First, let’s explore the difference between value objects and pointer objects in terms of memory address when passed to different functions. We create two functions as follows:
func TestValueAddress(t *testing.T) {
nest1 := func() S {
nest2 := func() S {
s := byValue()
fmt.Println("------ nest2 ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
return s
}
s := nest2()
fmt.Println("------ nest1 ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
return s
}
s := nest1()
fmt.Println("------ main ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
}
func TestPointAddress(t *testing.T) {
nest1 := func() *S {
nest2 := func() *S {
s := byPoint()
fmt.Println("------ nest2 ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
return s
}
s := nest2()
fmt.Println("------ nest1 ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
return s
}
s := nest1()
fmt.Println("------ main ------")
fmt.Printf("&a:%v, &b:%v, &c:%v, &d:%v, &f:%v, &g:%v, &h:%v, &i: %v\n",
&s.a, &s.b, &s.c, &s.d, &s.f, &s.g, &s.h, &s.i)
}
The corresponding input for the two methods is as follows:
// TestValueAddress output
------ nest2 ------
&a:0xc00007e2a0, &b:0xc00007e2a8, &c:0xc00007e2b0, &d:0xc00007e2b8, &f:0xc00007e2d8, &g:0xc00007e2e8, &h:0xc00007e2f0, &i: 0xc00007e2f8
------ nest1 ------
&a:0xc00007e240, &b:0xc00007e248, &c:0xc00007e250, &d:0xc00007e258, &f:0xc00007e278, &g:0xc00007e288, &h:0xc00007e290, &i: 0xc00007e298
------ main ------
&a:0xc00007e1e0, &b:0xc00007e1e8, &c:0xc00007e1f0, &d:0xc00007e1f8, &f:0xc00007e218, &g:0xc00007e228, &h:0xc00007e230, &i: 0xc00007e238
// TestPointAddress output
------ nest2 ------
&a:0xc00007e1e0, &b:0xc00007e1e8, &c:0xc00007e1f0, &d:0xc00007e1f8, &f:0xc00007e218, &g:0xc00007e228, &h:0xc00007e230, &i: 0xc00007e238
------ nest1 ------
&a:0xc00007e1e0, &b:0xc00007e1e8, &c:0xc00007e1f0, &d:0xc00007e1f8, &f:0xc00007e218, &g:0xc00007e228, &h:0xc00007e230, &i: 0xc00007e238
------ main ------
&a:0xc00007e1e0, &b:0xc00007e1e8, &c:0xc00007e1f0, &d:0xc00007e1f8, &f:0xc00007e218, &g:0xc00007e228, &h:0xc00007e230, &i: 0xc00007e238
From this we can see that the value object’s life cycle follows the function because it is allocated on the stack memory: when the function execution is complete, the object corresponding to the function will also be destroyed and copied to a new stack memory. The pointer object is allocated in heap memory, so even if the function execution is complete and the stack memory is cleaned up, its allocated memory address will not change. Instead, it is managed by the GC.
Therefore, when a value object is passed between different functions, it will inevitably cause a copy in the stack memory
Performance #
Let’s now look at the performance of value objects and pointer objects in just one function.
A benchmark was created to track its performance in a loop:
func BenchmarkValueCopy(b *testing.B) {
var s S
out, _ := os.Create("value.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
s = byValue()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
func BenchmarkPointCopy(b *testing.B) {
var s *S
out, _ := os.Create("point.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
s = byPoint()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
Then execute the following statements
go test -bench=BenchmarkValueCopy -benchmem -run=^$ -count=10 > value.txt
go test -bench=BenchmarkPointCopy -benchmem -run=^$ -count=10 > point.txt
The benchmark stat is as follows:
// value.txt
BenchmarkValueCopy-8 225915150 5.287 ns/op 0 B/op 0 allocs/op
BenchmarkValueCopy-8 225969075 5.348 ns/op 0 B/op 0 allocs/op
BenchmarkValueCopy-8 224717500 5.441 ns/op 0 B/op 0 allocs/op
...
// point.txt
BenchmarkPointCopy-8 22525324 47.25 ns/op 96 B/op 1 allocs/op
BenchmarkPointCopy-8 25844391 46.27 ns/op 96 B/op 1 allocs/op
BenchmarkPointCopy-8 25628395 46.02 ns/op 96 B/op 1 allocs/op
...
This shows that the initialization of the value object is faster than the initialization of the pointer object
Then we look at the specific reasons through the trace log, using the following commands:
go tool trace value.out
go tool trace point.out

value.out
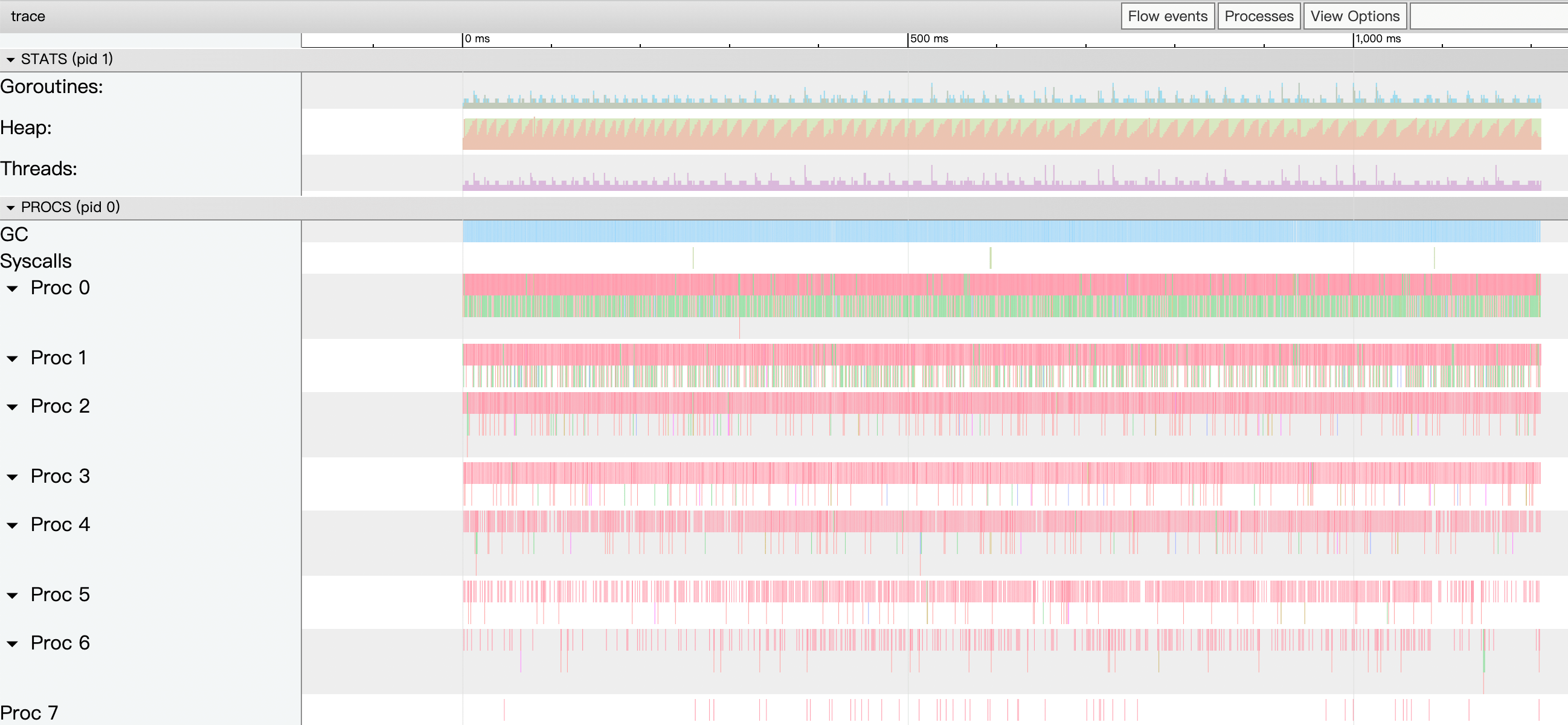
point.out
As can be seen from the trace log, the value object is not GC’d and there are no additional goroutines during execution; the pointer object is GC’d a total of 967 times.
Method execution #
Create an empty function based on the value object and pointer object as follows:
func (s S) value(s1 S) {}
func (s *S) point(s1 *S) {}
The corresponding Benchmark is as follows:
func BenchmarkValueFunction(b *testing.B) {
var s S
var s1 S
s = byValue()
s1 = byValue()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.value(s1)
}
}
}
func BenchmarkPointFunction(b *testing.B) {
var s *S
var s1 *S
s = byPoint()
s1 = byPoint()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.point(s1)
}
}
}
The benchmark statistics are as follows:
// value
BenchmarkValueFunction-8 160 7339292 ns/op
// point
BenchmarkPointFunction-8 480 2520106 ns/op
This shows that pointer objects are superior to value objects during method execution.
Arrays #
Next, we try to construct an array of value objects and an array of pointer objects, i.e. []S and []*S
func BenchmarkValueArray(b *testing.B) {
var s []S
out, _ := os.Create("value_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byValue())
}
}
trace.Stop()
b.StopTimer()
}
func BenchmarkPointArray(b *testing.B) {
var s []*S
out, _ := os.Create("point_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byPoint())
}
}
trace.Stop()
b.StopTimer()
}
The obtained benchmark stat is as follows
// value array []S
BenchmarkValueArray-8 2 542506184 ns/op 516467388 B/op 83 allocs/op
BenchmarkValueArray-8 2 532587916 ns/op 516469084 B/op 85 allocs/op
BenchmarkValueArray-8 3 501410289 ns/op 538334434 B/op 57 allocs/op
// point array []*S
BenchmarkPointArray-8 8 232675024 ns/op 145332278 B/op 1000022 allocs/op
BenchmarkPointArray-8 10 181305981 ns/op 145321713 B/op 1000018 allocs/op
BenchmarkPointArray-8 8 329801938 ns/op 145331643 B/op 1000021 allocs/op
Then use the trace log to see the specific GC and Goroutines:
go tool trace value_array.out
go tool trace point_array.out

value_array.out
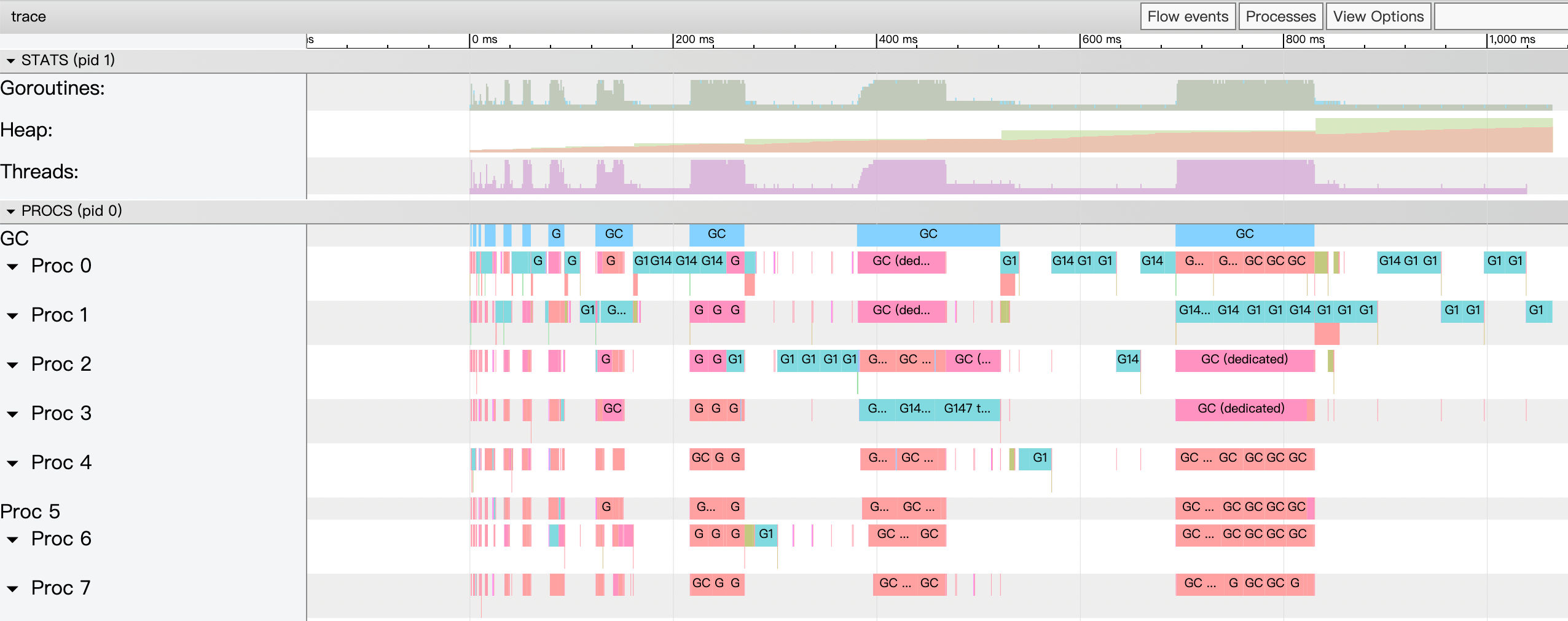
point_array.out
From the above log, we can see that []S still has fewer GC and Goroutines than []*S, but in actual running speed, especially in situations where value passing is required, []*S is still better than []S. In addition, there will be problems when using []S to modify the value of one of the items, as follows
// bad case
func TestValueArrayChange(t *testing.T) {
var s []S
for i := 0; i < 10; i++ {
s = append(s, byValue())
}
for _, v := range s {
v.a = 1
}
// assert failed
// Expected :int64(1)
// Actual :int64(-9223372036854775808)
assert.Equal(t, int64(1), s[0].a)
}
// good case
func TestPointArrayChange(t *testing.T) {
var s []*S
for i := 0; i < 10; i++ {
s = append(s, byPoint())
}
for _, v := range s {
v.a = 1
}
// assert success
assert.Equal(t, int64(1), s[0].a)
}
Summary #
As mentioned at the beginning, value objects are stored on the stack following the function, while pointer objects are stored in heap memory.
For value objects, when func ends, the value objects in the stack are also copied from one stack to another; at the same time, storing in stack memory means less GC and Goroutines.
For pointer objects, storing in heap memory will inevitably increase GC and Goroutines, but when passing pointer objects in func, only the pointer needs to be passed.
In summary, for objects that are only used within a method, or for small objects that you want to pass across methods, you can use value objects to improve efficiency and reduce GC. However, if you need to pass large objects, or pass objects across more methods, it is best to use pointer objects to pass them.
Further reading #
Go: Should I Use a Pointer instead of a Copy of my Struct?
Design Philosophy On Data And Semantics
Frequently Asked Questions (FAQ) - The Go Programming Language