

Introduction #
In March 2023, OPENAI released the GPT-4 multimodal model. The term “multimodal” entered public awareness for the first time. However, at that time, AI applications were still predominantly conversation-based products, and open-source models were relatively behind in supporting “multimodal” functionality.
Later that year, several research institutions and open-source model developers began releasing various open-source multimodal models:
- On April 17, 2023, Microsoft Research, the University of Wisconsin, and Columbia University researchers trained LLaVA based on the open-source model Vicuna (fine-tuned from LLaMA) and OPENAI’s open-source CLIP as the visual encoder
- On August 24, 2023, Alibaba released Qwen-VL based on the Qwen large language model and ViT
As for LLaMA and DeepSeek, they didn’t release official multimodal open-source models until 2024
- On March 14, 2024, DeepSeek released DeepSeek-VL
- On September 25, 2024, Meta released LLaMA-3.2-Vision(Llama 3.2: Revolutionizing edge AI and vision with open, customizable models)
My aim is to provide a beginner’s perspective on understanding how multimodal implementation works.
Vision Transformer (ViT) #
Vision Transformer was first proposed by Google Research’s Google Brain team in October 2020, in a paper titled An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.
The specific code repository is available at google-research/vision_transformer.
Let’s start by examining the paper

Simply put, ViT divides images into fixed-size blocks, then performs linear embedding on each block, adds corresponding position embeddings, and feeds them into a standard Transformer architecture.
For example, an original image with resolution (\(H,W)\) is divided into patches with resolution (\(P,P)\). The number of patches is (\(N = HW/P^2)\), which serves as the effective input sequence length for the Transformer. Assuming all layers in the Transformer have a latent vector size of (\(D)\), these patches are mapped to (\(D)\) dimensions through a trainable linear projection.
## https://github.com/google-research/vision_transformer/blob/main/vit_jax/models_vit.py
class VisionTransformer(nn.Module):
"""VisionTransformer."""
transformer: Any
encoder: Type[nn.Module] = Encoder
...
@nn.compact
def __call__(self, inputs, *, train):
x = inputs
...
## We can merge s2d+emb into a single conv; it's the same.
x = nn.Conv(
features=self.hidden_size,
kernel_size=self.patches.size,
strides=self.patches.size,
padding='VALID',
name='embedding')(
x)
## Here, x is a grid of embeddings.
## (Possibly partial) Transformer.
if self.transformer is not None:
n, h, w, c = x.shape
x = jnp.reshape(x, [n, h * w, c])
...
x = self.encoder(name='Transformer', **self.transformer)(x, train=train)
...
class Encoder(nn.Module):
"""Transformer Model Encoder for sequence to sequence translation.
Attributes:
num_layers: number of layers
mlp_dim: dimension of the mlp on top of attention block
num_heads: Number of heads in nn.MultiHeadDotProductAttention
dropout_rate: dropout rate.
attention_dropout_rate: dropout rate in self attention.
"""
num_layers: int
mlp_dim: int
num_heads: int
dropout_rate: float = 0.1
attention_dropout_rate: float = 0.1
add_position_embedding: bool = True
@nn.compact
def __call__(self, x, *, train):
assert x.ndim == 3 ## (batch, len, emb)
## Position Encoder
if self.add_position_embedding:
x = AddPositionEmbs(
posemb_init=nn.initializers.normal(stddev=0.02), ## from BERT.
name='posembed_input')(
x)
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=not train)
## Input Encoder
for lyr in range(self.num_layers):
x = Encoder1DBlock(
mlp_dim=self.mlp_dim,
dropout_rate=self.dropout_rate,
attention_dropout_rate=self.attention_dropout_rate,
name=f'encoderblock_{lyr}',
num_heads=self.num_heads)(
x, deterministic=not train)
encoded = nn.LayerNorm(name='encoder_norm')(x)
return encoded
So far, it’s still difficult to understand how the ViT model interprets images. In my opinion, the main purpose of the ViT model is to maximize the encoding of image information, ensuring that when tokens are passed to the Transformer, it can better understand the image
With this goal in mind, let’s look at how ViT processes images, using ViT-L/32 (a model based on BERT-Large with 32 x 32 patch division) as an example:
- The left image shows the filters after linear projection of RGB color blocks through ViT-L/32
- The middle image shows the position embedding of the patches
- The left image shows the mean attention distance calculated based on attention weights in image space, which can be understood as the receptive field
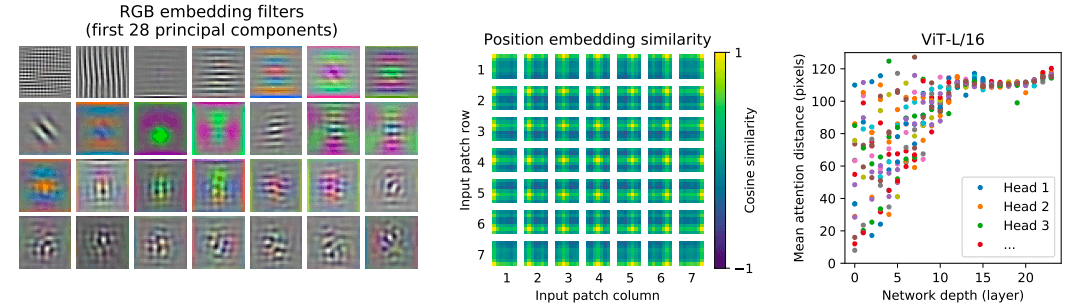
In addition, the team also compared the model’s token output with the actual input:

From these experiments, we can observe that the attention distance increases with network depth, and researchers found that the ViT model focuses more on image regions that are semantically relevant to classification.
Image-Text Alignment #
We’ve discussed how ViT converts images into tokens, but the next question is: how does the model understand and learn these tokens? When users input both images and text, how does the model combine and understand them together?
This section introduces how multimodal models align image and text tokens, as well as related training methods, to implement multimodality.
OPENAI CLIP #
CLIP is a vision model proposed by OPENAI in 2021, in a paper titled Learning Transferable Visual Models From Natural Language Supervision. OPENAI’s official open-source repository is openai/CLIP, and the community later led a project called mlfoundations/open_clip that supports more datasets, ViT architectures, and more.
In training tasks, CLIP is used to determine the matching degree between text and images. When trained with sufficient data, the model can predict text more relevant to images, thereby performing image classification and text completion.
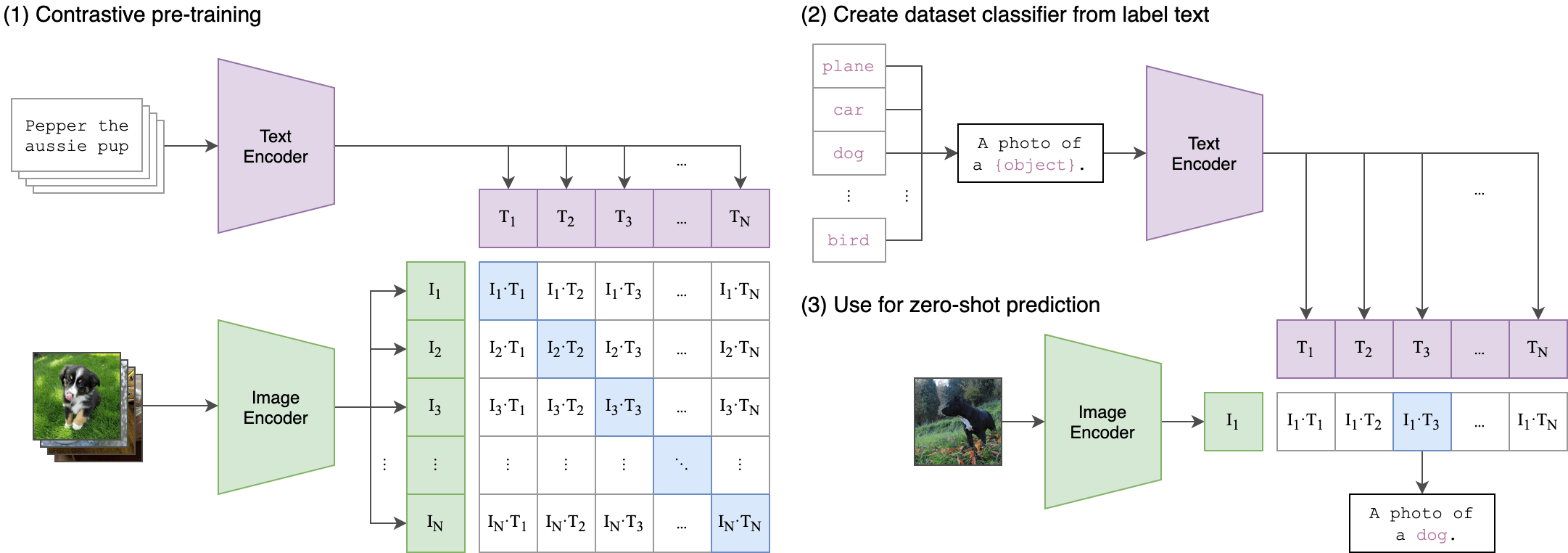
CLIP has two important components:
- Text Encoder (text embedding): It directly uses a 12-layer Transformer with 63M parameters
- Image Encoder (image embedding): ① Uses a standard ResNet-50 as the image encoder ② Uses the Vision Transformer we mentioned above as the image encoder, with a small modification: adding layer normalization to patch and position embeddings
Let’s break down the specific steps:
- First, compute feature embeddings using the text encoder and image encoder
- Then calculate the cosine similarity of the embeddings and scale with a temperature parameter
- Use softmax to normalize into probability distributions, detecting the matching degree between text and images
In simple terms, the image encoder works similarly to traditional CV models, outputting feature representations of images. Assuming the model learns N classifications, the feature representations produced by the text encoder serve as the weights of the “classifier,” calculating the closest classification for the final output.
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
## vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
## text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
self.context_length = context_length
## image encoder
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
## text encoder
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) ## [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) ## NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) ## LND -> NLD
x = self.ln_final(x).type(self.dtype)
## x.shape = [batch_size, n_ctx, transformer.width]
## take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
## normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
## cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
## shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
SigLIP & SigLIT #
Google proposed Sigmoid Loss for Language Image Pre-Training in March 2023, which is mainly an optimization approach for the CLIP model pre-training process. The key improvement is in the calculation of the loss function.
- Sigmoid combined with OPENAI’s CLIP is named SigLIP
- Sigmoid combined with Google’s CLIP-based optimization LIT is named SigLiT (LIT is not covered in this article, but if you’re interested, you can check out LiT: Zero-Shot Transfer with Locked-image text Tuning)
This part is relatively dry and abstract, so let’s explain it with some code examples.
Let’s look at the loss function definitions in the mlfoundations/open_clip project.
First, let’s examine CLIP’s own loss function, which uses the cross_entropy function to calculate contrastive loss and softmax to calculate distillation loss.
class DistillClipLoss(ClipLoss):
def dist_loss(self, teacher_logits, student_logits):
return -(teacher_logits.softmax(dim=1) * student_logits.log_softmax(dim=1)).sum(dim=1).mean(dim=0)
def forward(
self,
image_features,
text_features,
logit_scale,
dist_image_features,
dist_text_features,
dist_logit_scale,
output_dict=False,
):
logits_per_image, logits_per_text = \
self.get_logits(image_features, text_features, logit_scale)
dist_logits_per_image, dist_logits_per_text = \
self.get_logits(dist_image_features, dist_text_features, dist_logit_scale)
labels = self.get_ground_truth(image_features.device, logits_per_image.shape[0])
contrastive_loss = (
## cross entroy
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
distill_loss = (
## softmax
self.dist_loss(dist_logits_per_image, logits_per_image) +
self.dist_loss(dist_logits_per_text, logits_per_text)
) / 2
if output_dict:
return {"contrastive_loss": contrastive_loss, "distill_loss": distill_loss}
return contrastive_loss, distill_loss
Now let’s see how the Sigmoid loss is calculated. The key aspect is using logsigmoid to output probability logarithms when computing the loss.
class SigLipLoss(nn.Module):
""" Sigmoid Loss for Language Image Pre-Training (SigLIP) - https://arxiv.org/abs/2303.15343
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
"""
def __init__(
self,
cache_labels: bool = False,
rank: int = 0,
world_size: int = 1,
dist_impl: Optional[str] = None,
):
super().__init__()
self.cache_labels = cache_labels
self.rank = rank
self.world_size = world_size
self.dist_impl = dist_impl or 'bidir' ## default to bidir exchange for now, this will likely change
assert self.dist_impl in ('bidir', 'shift', 'reduce', 'gather')
## cache state FIXME cache not currently used, worthwhile?
self.prev_num_logits = 0
self.labels = {}
def get_ground_truth(self, device, dtype, num_logits, negative_only=False) -> torch.Tensor:
labels = -torch.ones((num_logits, num_logits), device=device, dtype=dtype)
if not negative_only:
labels = 2 * torch.eye(num_logits, device=device, dtype=dtype) + labels
return labels
def get_logits(self, image_features, text_features, logit_scale, logit_bias=None):
logits = logit_scale * image_features @ text_features.T
if logit_bias is not None:
logits += logit_bias
return logits
def _loss(self, image_features, text_features, logit_scale, logit_bias=None, negative_only=False):
logits = self.get_logits(image_features, text_features, logit_scale, logit_bias)
labels = self.get_ground_truth(
image_features.device,
image_features.dtype,
image_features.shape[0],
negative_only=negative_only,
)
## logsigmoid
loss = -F.logsigmoid(labels * logits).sum() / image_features.shape[0]
return loss
def forward(self, image_features, text_features, logit_scale, logit_bias, output_dict=False):
loss = self._loss(image_features, text_features, logit_scale, logit_bias)
if self.world_size > 1:
if self.dist_impl == 'bidir':
right_rank = (self.rank + 1) % self.world_size
left_rank = (self.rank - 1 + self.world_size) % self.world_size
text_features_to_right = text_features_to_left = text_features
num_bidir, remainder = divmod(self.world_size - 1, 2)
for i in range(num_bidir):
text_features_recv = neighbour_exchange_bidir_with_grad(
left_rank,
right_rank,
text_features_to_left,
text_features_to_right,
)
for f in text_features_recv:
loss += self._loss(
image_features,
f,
logit_scale,
logit_bias,
negative_only=True,
)
text_features_to_left, text_features_to_right = text_features_recv
if remainder:
text_features_recv = neighbour_exchange_with_grad(
left_rank,
right_rank,
text_features_to_right
)
loss += self._loss(
image_features,
text_features_recv,
logit_scale,
logit_bias,
negative_only=True,
)
elif self.dist_impl == "shift":
right_rank = (self.rank + 1) % self.world_size
left_rank = (self.rank - 1 + self.world_size) % self.world_size
text_features_to_right = text_features
for i in range(self.world_size - 1):
text_features_from_left = neighbour_exchange_with_grad(
left_rank,
right_rank,
text_features_to_right,
)
loss += self._loss(
image_features,
text_features_from_left,
logit_scale,
logit_bias,
negative_only=True,
)
text_features_to_right = text_features_from_left
elif self.dist_impl == "reduce":
for i in range(self.world_size):
text_from_other = torch.distributed.nn.all_reduce(
text_features * (self.rank == i),
torch.distributed.ReduceOp.SUM,
)
loss += float(i != self.rank) * self._loss(
image_features,
text_from_other,
logit_scale,
logit_bias,
negative_only=True,
)
elif self.dist_impl == "gather":
all_text = torch.distributed.nn.all_gather(text_features)
for i in range(self.world_size):
loss += float(i != self.rank) * self._loss(
image_features,
all_text[i],
logit_scale,
logit_bias,
negative_only=True,
)
else:
assert False
return {"contrastive_loss": loss} if output_dict else loss
Multimodal Models #
Qwen Vision #
Qwen-VL #
The first version of the Qwen multimodal model was proposed in August 2023. The specific paper is Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond, with model weights available at [HuggingFace] Qwen/Qwen-VL, and official code for fine-tuning and training at [Github] QwenLM/Qwen-VL.
First, we need to understand the overall structure of Qwen-VL, which is mentioned at the beginning of the paper.
Qwen-VL’s overall architecture consists of three components:
- Large Language Model: Uses Qwen-7B as the base component, initialized with Qwen-7B pre-trained weights.
- Vision Encoder: Uses the Vision Transformer (ViT) architecture, specifically based on openclip’s ViT-bigG-14, which divides images into 14*14 patches to generate image features. (Qwen-VL’s vision encoder only supports input up to 448 * 448)
- Position-aware Vision-Language Adapter: To mitigate efficiency issues caused by long image feature sequences, a vision-language adapter is used to compress image features. This is implemented as a single-layer cross-attention module that can compress visual feature sequences to 256.
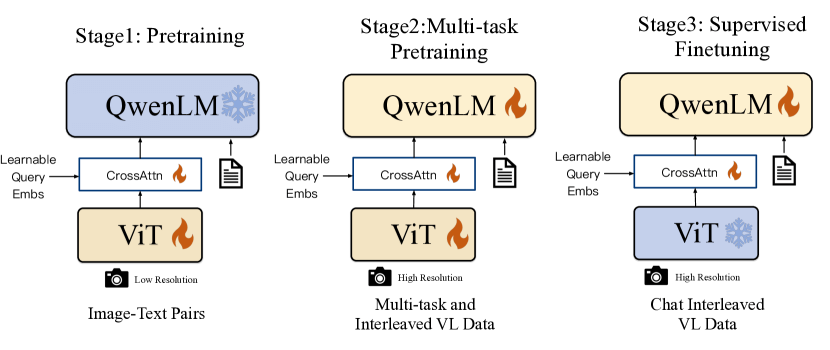
Below is the code related to these three components:
## https://huggingface.co/Qwen/Qwen-VL/blob/main/modeling_qwen.py
class QWenModel(QWenPreTrainedModel):
...
def __init__(self, config):
super().__init__(config)
...
## large language model
self.h = nn.ModuleList(
[
QWenBlock(
config
)
for i in range(config.num_hidden_layers)
]
)
self.ln_f = RMSNorm(
self.embed_dim,
eps=config.layer_norm_epsilon,
)
## vision model
self.visual = VisionTransformer(**config.visual)
self.post_init()
## https://huggingface.co/Qwen/Qwen-VL/blob/main/visual.py
class VisionTransformer(nn.Module):
def __init__(
self,
image_size: int,
patch_size: int,
width: int,
layers: int,
heads: int,
mlp_ratio: float,
n_queries: int = 256,
output_dim: int = 512,
**kwargs
):
...
self.transformer = TransformerBlock(
width,
layers,
heads,
mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
)
## **Position-aware Vision-Language Adapter**
self.attn_pool = Resampler(
grid_size=int(math.sqrt(n_queries)),
embed_dim=output_dim,
num_heads=output_dim // 128,
kv_dim=width,
norm_layer=norm_layer,
)
...
class Resampler(nn.Module):
"""
A 2D perceiver-resampler network with one cross attention layers by
(grid_size**2) learnable queries and 2d sincos pos_emb
Outputs:
A tensor with the shape of (grid_size**2, embed_dim)
"""
def __init__(
self,
grid_size,
embed_dim,
num_heads,
kv_dim=None,
norm_layer=nn.LayerNorm
):
...
In addition, to help the model better distinguish between images and text, Qwen-VL added several special token identifiers in the sequence:
- For image inputs,
<img>and</img>tags are added at the beginning and end of image feature sequences to represent the start and end of image content - During training, Qwen-VL deals with region descriptions, questions, and detection tasks. For these contents, Qwen-VL adds
<box>and</box>tags at the beginning and end of bounding boxes, while adding<ref>and</ref>tags for content referenced by these boxes
This part of the code is mainly implemented in QWenTokenizer:
class QWenTokenizer(PreTrainedTokenizer):
"""QWen tokenizer."""
vocab_files_names = VOCAB_FILES_NAMES
def __init__(
self,
vocab_file,
errors="replace",
image_start_tag='<img>',
image_end_tag='</img>',
image_pad_tag='<imgpad>',
ref_start_tag='<ref>',
ref_end_tag='</ref>',
box_start_tag='<box>',
box_end_tag='</box>',
quad_start_tag='<quad>',
quad_end_tag='</quad>',
**kwargs,
):
...
self.img_start_id = self.special_tokens[self.image_start_tag]
self.img_end_id = self.special_tokens[self.image_end_tag]
self.img_pad_id = self.special_tokens[self.image_pad_tag]
self.ref_start_id = self.special_tokens[self.ref_start_tag]
self.ref_end_id = self.special_tokens[self.ref_end_tag]
self.box_start_id = self.special_tokens[self.box_start_tag]
self.box_end_id = self.special_tokens[self.box_end_tag]
self.quad_start_id = self.special_tokens[self.quad_start_tag]
self.quad_end_id = self.special_tokens[self.quad_end_tag]
...
def to_list_format(self, text: str):
...
def _encode_vl_info(tokens):
if len(tokens) == 0:
return []
if tokens[0] == self.img_start_id and tokens[-1] == self.img_end_id:
key = 'image'
elif tokens[0] == self.ref_start_id and tokens[-1] == self.ref_end_id:
key = 'ref'
elif tokens[0] == self.box_start_id and tokens[-1] == self.box_end_id:
key = 'box'
elif tokens[0] == self.quad_start_id and tokens[-1] == self.quad_end_id:
key = 'quad'
else:
_tobytes = lambda x: x.encode('utf-8') if isinstance(x, str) else x
return [{'text': b''.join(map(_tobytes, map(self.decoder.get, tokens))).decode('utf-8')}]
_tobytes = lambda x: x.encode('utf-8') if isinstance(x, str) else x
val = b''.join(map(_tobytes, map(self.decoder.get, tokens[1:-1]))).decode('utf-8')
return [{key: val}]
return _replace_closed_tag(
token_ids,
(self.img_start_id, self.ref_start_id, self.box_start_id, self.quad_start_id),
(self.img_end_id, self.ref_end_id, self.box_end_id, self.quad_end_id),
_encode_vl_info,
_encode_vl_info,
)
Qwen2-VL #
A year later, Alibaba released Qwen2-VL in September 2024, with the corresponding paper Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. The model is available at [HuggingFace] Qwen2-VL
Compared to Qwen-VL, Qwen2-VL doesn’t have significant architectural changes, maintaining the language model + vision encoder architecture. Additionally, Qwen2-VL supports video formats and optimized model perception, specifically in the following aspects:
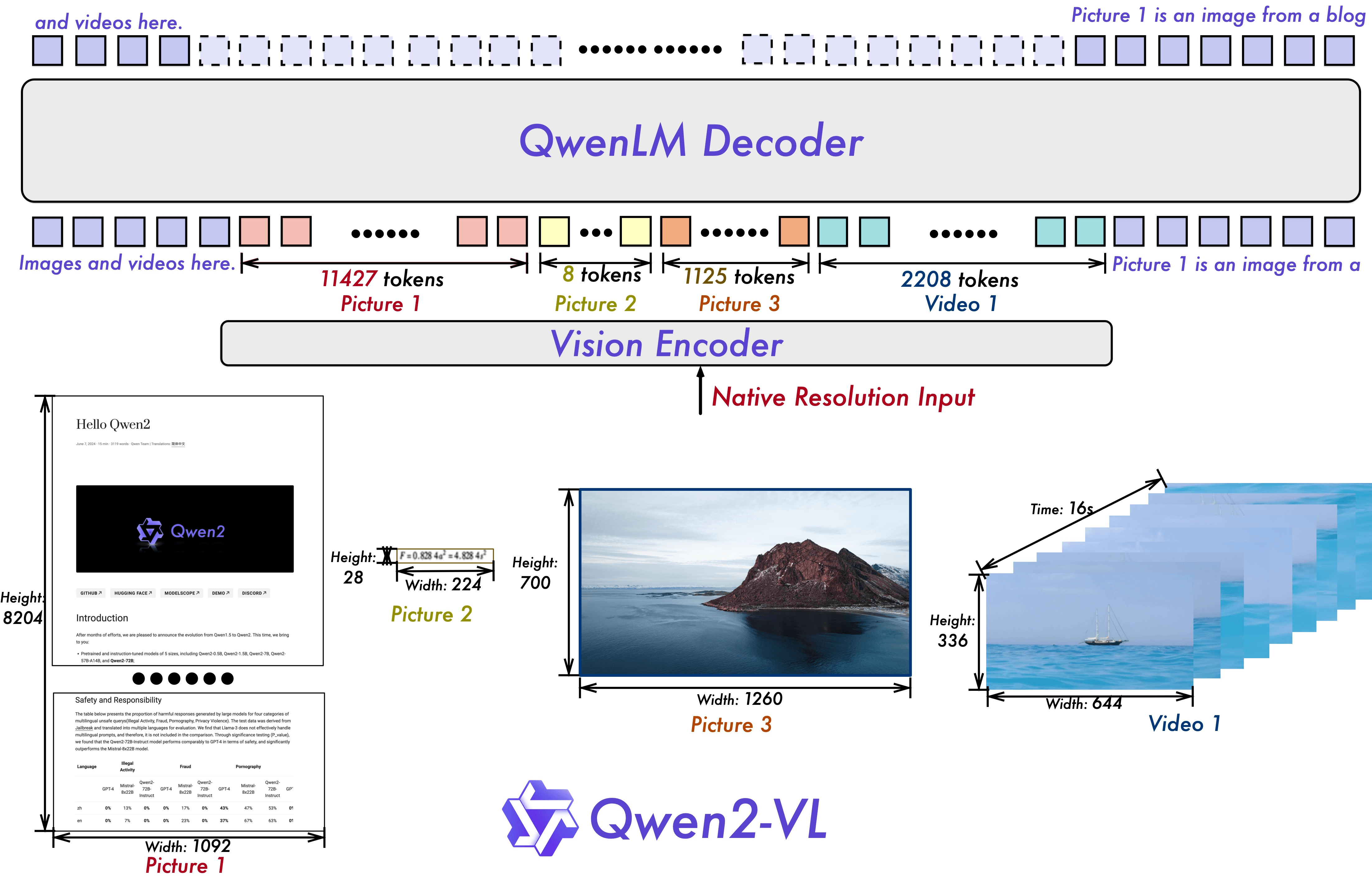
First, Qwen2-VL supports dynamic resolution (Naive Dynamic Resolution), allowing it to process images of any resolution. This implementation is based on 2D Rotary Position Embedding (2D-RoPE), which removes absolute positions from the original image and captures two-dimensional positions through relative positioning.
Furthermore, after the ViT, an MLP layer is used to compress adjacent 2 x 2 tokens into a single token, with <|vision_start|> and <|vision_end|> tags placed at the beginning and end of the compressed tokens. For example, a 224x224 resolution image, encoded with a ViT using patch_size=14, is divided into 16 * 16 (256) tokens, then compressed to 64 tokens, plus the start and end tags for a total of 66 tokens.
Second, Qwen2-VL introduces Multimodal Rotary Position Embedding (M-RoPE). While 2D-RoPE is mainly used for images, M-RoPE applies to both text and images. M-RoPE defines rotational positions for different modalities through time, height, and width.
- For text input, the same position IDs are used, making M-RoPE equivalent to 1D-RoPE
- For image input, time IDs remain constant, while height and width positions are assigned based on the patch’s relative position in the image, similar to 2D-RoPE
- For video input, time IDs increment with each frame sequence, while height and width are assigned based on the patch’s relative position in the current frame
- For multi-modal inputs, each modality’s position numbering is determined by incrementing the previous modality’s maximum position ID by 1

Finally, there are some optimizations, such as:
- Videos are sampled at a default rate of 2 frames per second
- The total number of tokens per video is limited to 16384
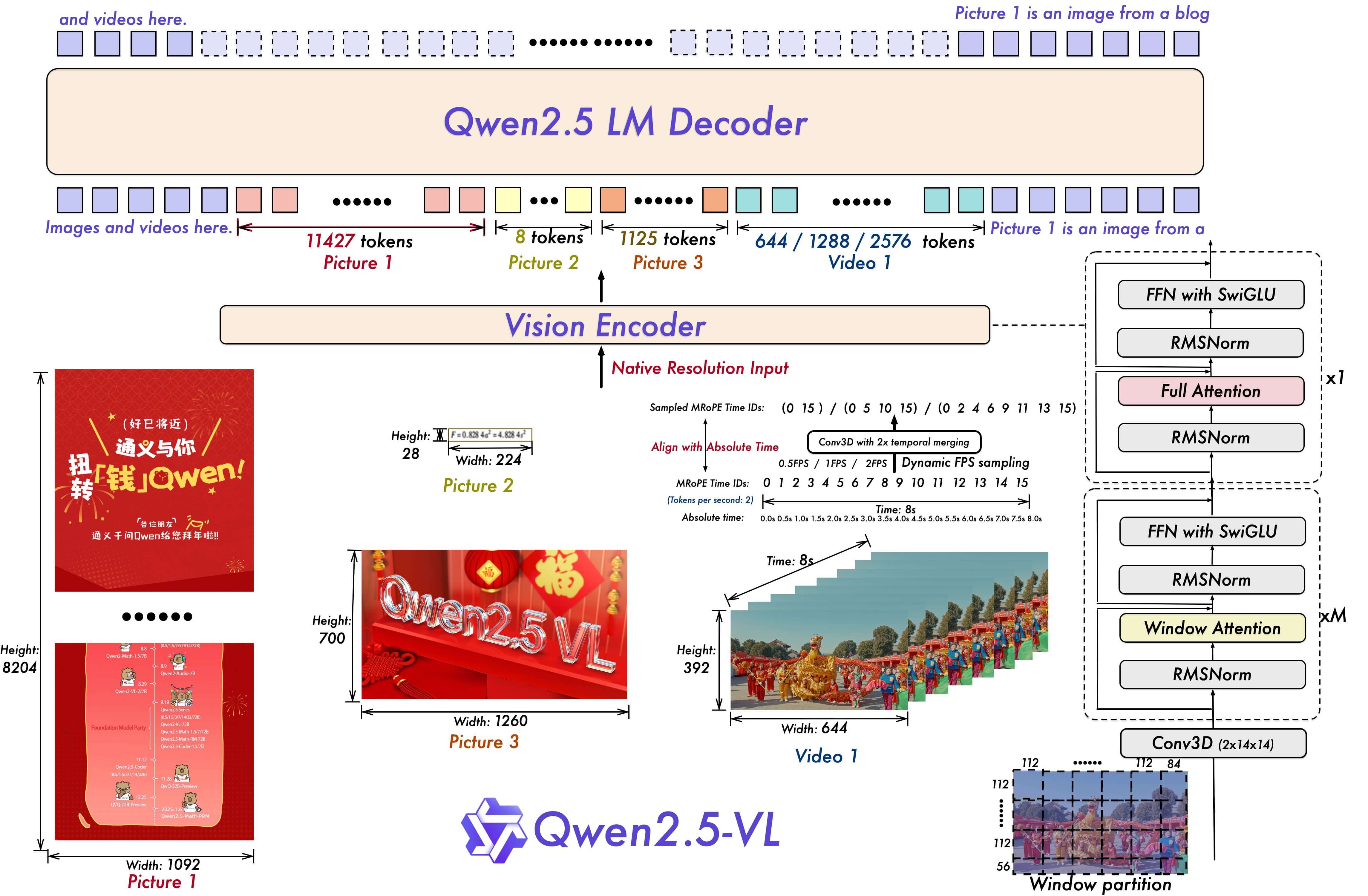
Qwen2.5-VL #
Qwen2.5-VL was released by Alibaba in February 2025, with the corresponding paper Qwen2.5-VL Technical Report, and codebase at QwenLM/Qwen2.5-VL.
However, being only about half a year after Qwen2-VL, the overall changes are not significant, mainly focusing on detailed improvements:
- The large language model was upgraded to Qwen2.5
- The ViT was redesigned, but still uses 2D-RoPE and window attention mechanisms
- For video content, dynamic frame rates are used for video capture. The time ID in M-RoPE, which was auto-incrementing in Qwen2-VL, was changed to align with timestamps to learn consistent time alignment across different FPS sampling rates.
- Qwen2.5-VL also supports document parsing, but instead of traditional separate extraction of document layout, text, tables, and illustrations, it uniformly converts everything to HTML format to represent the overall document layout, text, tables, illustrations, and other content.
Other aspects are mainly related to training, which won’t be covered here.
DeepSeek Vision #
DeepSeek-VL #
DeepSeek released its multimodal model much later than Qwen, around March 2024.
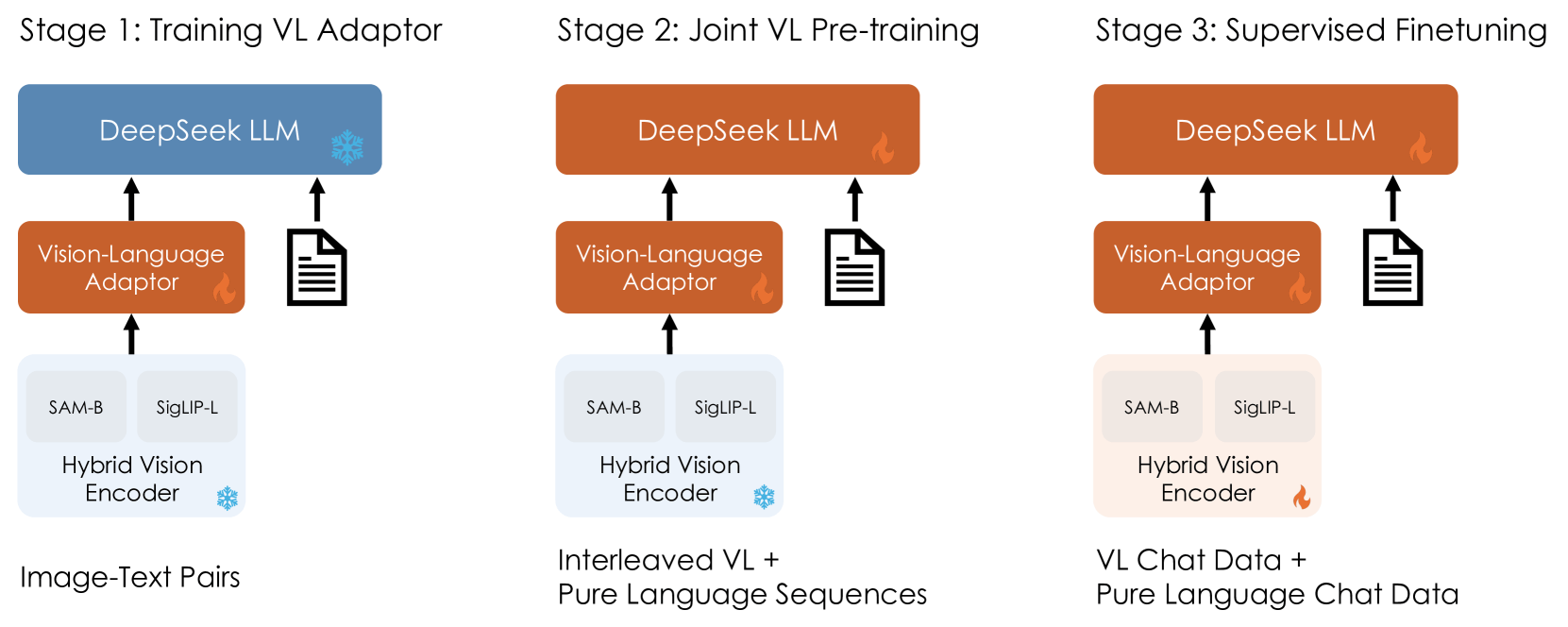
The first released DeepSeek-VL was based on DeepSeek v1’s dense model architecture. The specific paper is DeepSeek-VL: Towards Real-World Vision-Language Understanding, with the corresponding codebase at deepseek-ai/DeepSeek-VL.
Similarly to Qwen-VL, it also consists of three main modules: Large Language Model, Vision-Language Adapter, and Hybrid Visual Encoder.
The Large Language Model is built on DeepSeek LLM, which needs no further explanation; the Vision-Language Encoder uses a two-layer hybrid multilayer perceptron (MLP) to connect the visual encoder and LLM. The two-layer design is necessary due to the hybrid visual encoder, with separate layers processing high-resolution and low-resolution features.
The key component to highlight is the Hybrid Visual Encoder.
Unlike Qwen which uses ViT as the encoder, DeepSeek-VL employs a hybrid visual encoder combining SigLIP (siglip_large_patch16_384) + SAM-B (sam_b_downsample).
- Meta’s open-source SAM-B encoder receives high-resolution image input, better preserving image details (referenced in [2023.04] Segment Anything)
- The SigLIP-L encoder with low-resolution image input is retained to preserve semantic content
Let’s briefly explain the processing flow of these two encoders. First, before entering the encoders, images are resized to 1024 * 1024 resolution.
The SAM-B encoder transforms the 1024 * 1024 high-resolution image into a 64 * 64 * 256 feature map, where 256 can be understood as the dimension or channel; the VL adapter interpolates it to a 96 * 96 * 256 feature map; then through two convolutional layers with stride 2 for downsampling, it generates 48 * 48 * 512 and 24 * 24 * 1024 feature maps respectively; finally, this 24 * 24 * 1024 feature map is reshaped to 576 x 1024, meaning 576 tokens with 1024 dimensions each.
## https://github.com/deepseek-ai/DeepSeek-VL/blob/main/deepseek_vl/models/sam.py
def create_sam_vit(
model_name: str = "sam_b_downsample",
image_size: int = 1024,
ckpt_path: str = "",
**kwargs,
):
...
sam_cfg = SAMViTCfg(**SAM_MODEL_CONFIG[model_name])
image_encoder = ImageEncoderViT(
depth=sam_cfg.layers,
embed_dim=sam_cfg.width,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=sam_cfg.heads,
patch_size=sam_cfg.patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=sam_cfg.global_attn_indexes,
window_size=14,
out_chans=sam_cfg.prompt_embed_dim,
downsample_channels=sam_cfg.downsample_channels,
)
...
## This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py ## noqa
class ImageEncoderViT(nn.Module):
...
def forward(self, x: torch.Tensor) -> torch.Tensor:
## patch embedding
x = self.patch_embed(x)
if self.pos_embed is not None:
## position embedding
x = x + self.pos_embed
global_features = []
for i, blk in enumerate(self.blocks):
x = blk(x)
if self.sam_hd and blk.window_size == 0:
global_features.append(x)
x = self.neck(x.permute(0, 3, 1, 2))
x_dtype = x.dtype
## -> 96 * 96 * 256
x = F.interpolate(
x.float(), size=(96, 96), mode="bilinear", align_corners=False
).to(x_dtype)
## -> 24 * 24 * 1024
x = self.downsamples(x)
if self.sam_hd:
first_global_feature = self.neck_hd(global_features[0].permute(0, 3, 1, 2))
x_dtype = first_global_feature.dtype
first_global_feature = F.interpolate(
first_global_feature.float(),
size=(96, 96),
mode="bilinear",
align_corners=False,
)
first_global_feature = self.downsamples(first_global_feature.to(x_dtype))
x = x + first_global_feature * self.hd_alpha_downsamples
return x
Below is the SigLIP encoder. DeepSeek-VL uses siglip_large_patch16_384, which takes input of 384 * 384, meaning the image resolution needs to be adjusted to 384 * 384. The patch_size is 16, which means it will be divided into 576 patches of 16 * 16, with each patch having 1024 dimensions, resulting in 576 * 1024.
## https://github.com/deepseek-ai/DeepSeek-VL/blob/main/deepseek_vl/models/siglip_vit.py
def create_siglip_vit(
model_name: str = "siglip_so400m_patch14_384",
image_size: int = 384,
select_layer: int = -1,
ckpt_path: str = "",
**kwargs,
):
...
vision_cfg = SigLIPVisionCfg(**SigLIP_MODEL_CONFIG[model_name])
model = VisionTransformer(
img_size=image_size,
patch_size=vision_cfg.patch_size,
embed_dim=vision_cfg.width,
depth=layers,
num_heads=vision_cfg.heads,
mlp_ratio=vision_cfg.mlp_ratio,
class_token=vision_cfg.class_token,
global_pool=vision_cfg.global_pool,
ignore_head=kwargs.get("ignore_head", True),
weight_init=kwargs.get("weight_init", "skip"),
num_classes=0,
)
After the explanation above, the image is ultimately transformed by the SAM-B encoder into 576 tokens with 1024 dimensions each; similarly, the SigLIP encoder also transforms the image into 576 tokens with 1024 dimensions. Let’s take a final look at the code for the hybrid encoder
## https://github.com/deepseek-ai/DeepSeek-VL/blob/main/deepseek_vl/models/clip_encoder.py
class CLIPVisionTower(nn.Module):
def build_vision_tower(self, vision_tower_params):
if self.model_name.startswith("siglip"):
self.select_feature = "same"
## siglip vit
vision_tower = create_siglip_vit(**vision_tower_params)
forward_kwargs = dict()
elif self.model_name.startswith("sam"):
## sam vit
vision_tower = create_sam_vit(**vision_tower_params)
forward_kwargs = dict()
else: ## huggingface
from transformers import CLIPVisionModel
vision_tower = CLIPVisionModel.from_pretrained(**vision_tower_params)
forward_kwargs = dict(output_hidden_states=True)
return vision_tower, forward_kwargs
class HybridVisionTower(nn.Module):
def __init__(
self,
high_res_cfg: Dict,
low_res_cfg: Dict,
freeze_high: bool = False,
freeze_low: bool = False,
concat_type: Literal["feature", "sequence", "add", "tuple"] = "tuple",
**ignore_kwargs,
):
super().__init__()
self.vision_tower_high = CLIPVisionTower(**high_res_cfg)
self.vision_tower_low = CLIPVisionTower(**low_res_cfg)
...
def forward(self, images: torch.Tensor):
"""
Args:
images (torch.Tensor): [bs, 3, H, W]
Returns:
res (torch.Tensor): [bs, t, c]
"""
## [bs, c, h, w]
high_images = images
## 1024 * 1024 -> 384 * 384
## [bs, c, h_low, w_low]
low_images = self.resize(images)
## separately run two vision towers
## run high_res vision tower
high_res = self.vision_tower_high(high_images)
## [bs, c, h, w] -> [bs, h*w, c]
high_res = rearrange(high_res, "b c h w -> b (h w) c")
## run low_res vision tower
low_res = self.vision_tower_low(low_images)
if self.concat_type == "feature":
images_features = torch.cat([high_res, low_res], dim=-1)
elif self.concat_type == "sequence":
images_features = torch.cat([high_res, low_res], dim=1)
elif self.concat_type == "add":
images_features = high_res + low_res
elif self.concat_type == "tuple":
images_features = (high_res, low_res)
else:
raise ValueError(
"Currently only support `feature`, `sequence`, `add` and `tuple` concat type."
)
return images_features
Training-related aspects won’t be covered in detail here; interested readers can refer to the paper and code.
DeepSeek-VL2 #
DeepSeek-VL2 uses DeepSeek-MoE as its base language model, which introduces its biggest innovation: a MoE (Mixture of Experts) multimodal model.
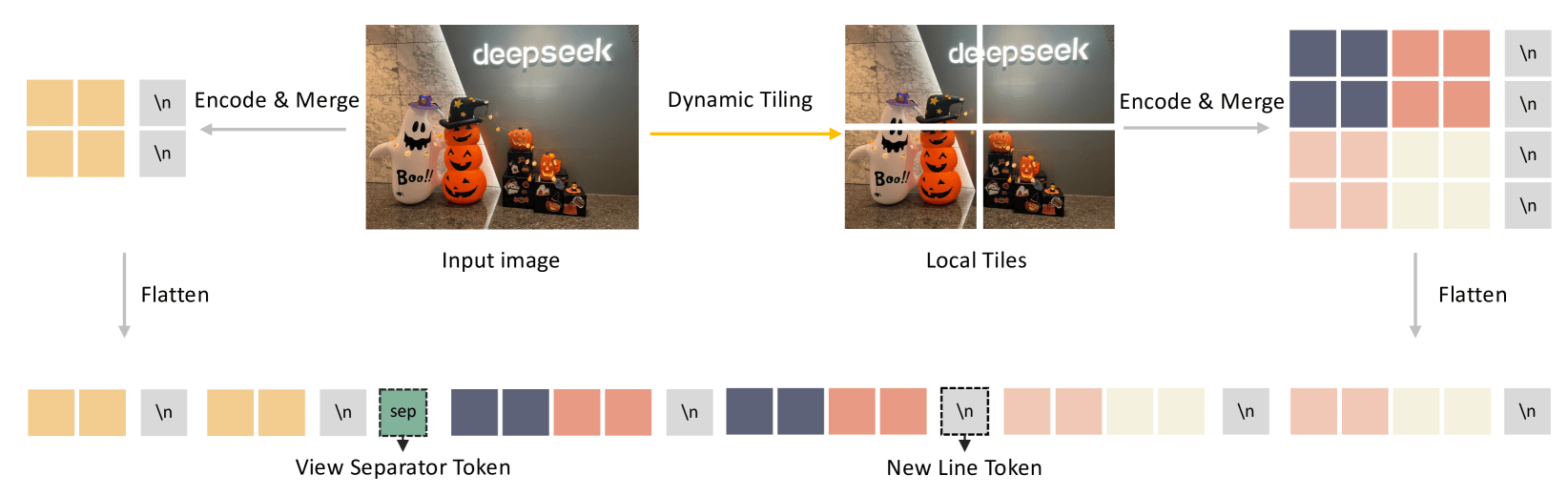
Additionally, while DeepSeek-VL employed a hybrid encoder (SAM-B for 1024×1024 resolution and SigLIP for 384×384 resolution), DeepSeek-VL2 introduces a dynamic tiling visual encoding strategy to handle images with different aspect ratios.

Compared to DeepSeek-VL, the VL2 approach is actually simpler, using only a single SigLIP encoder. Specifically, it uses siglip_so400m_patch14_384: accepting 384×384 input, dividing it into 14×14 patches, with a dimension of 1152, ultimately outputting 27×27=729 tokens with 1152 dimensions each.
The key focus is the dynamic tiling strategy. Since SigLIP takes 384×384 input, to accommodate different images, a set of candidate resolutions is predefined (\(C_R={(m \times 384, n\times 384)| 1 \le m,n,mn \le 9 })\), where (\(m:n)\) represents the aspect ratio. The input image is adjusted to each candidate resolution (\(m_i:n_i)\), then divided into 384×384 segments, resulting in (\(m_i \times n_i)\) blocks of 384×384, called local views. Additionally, DeepSeek-VL2 resizes the entire image to 384×384 resolution to obtain a global thumbnail block. Ultimately, we get (\(1 + m_i \times n_i)\) image blocks, all processed by siglip_so400m_patch14_384.
Let’s examine the relevant code
class DeepseekVLV2Processor(ProcessorMixin):
...
def tokenize_with_images(
self,
conversation: str,
images: List[Image.Image],
bos: bool = True,
eos: bool = True,
cropping: bool = True,
):
"""Tokenize text with <image> tags."""
...
images_list, images_seq_mask, images_spatial_crop = [], [], []
num_image_tokens = []
tokenized_str = []
for text_sep, image in zip(text_splits, images):
"""encode text_sep"""
tokenized_sep = self.encode(text_sep, bos=False, eos=False)
tokenized_str += tokenized_sep
images_seq_mask += [False] * len(tokenized_sep)
"""select best resolution for anyres"""
if cropping:
best_width, best_height = select_best_resolution(image.size, self.candidate_resolutions)
else:
best_width, best_height = self.image_size, self.image_size
## print(image.size, (best_width, best_height)) ## check the select_best_resolutions func
"""process the global view"""
global_view = ImageOps.pad(image, (self.image_size, self.image_size),
color=tuple(int(x * 255) for x in self.image_transform.mean))
images_list.append(self.image_transform(global_view))
"""process the local views"""
local_view = ImageOps.pad(image, (best_width, best_height),
color=tuple(int(x * 255) for x in self.image_transform.mean))
for i in range(0, best_height, self.image_size):
for j in range(0, best_width, self.image_size):
images_list.append(
self.image_transform(local_view.crop((j, i, j + self.image_size, i + self.image_size))))
"""record height / width crop num"""
num_width_tiles, num_height_tiles = best_width // self.image_size, best_height // self.image_size
images_spatial_crop.append([num_width_tiles, num_height_tiles])
"""add image tokens"""
h = w = math.ceil((self.image_size // self.patch_size) / self.downsample_ratio)
## global views tokens h * (w + 1), 1 is for line seperator
tokenized_image = [self.image_token_id] * h * (w + 1)
## add a seperator between global and local views
tokenized_image += [self.image_token_id]
## local views tokens, (num_height_tiles * h) * (num_width_tiles * w + 1)
tokenized_image += [self.image_token_id] * (num_height_tiles * h) * (num_width_tiles * w + 1)
tokenized_str += tokenized_image
images_seq_mask += [True] * len(tokenized_image)
num_image_tokens.append(len(tokenized_image))
## print(width_crop_num, height_crop_num, len(tokenized_image)) ## test the correctness of the number of image-related tokens
"""process the last text split"""
tokenized_sep = self.encode(text_splits[-1], bos=False, eos=False)
tokenized_str += tokenized_sep
images_seq_mask += [False] * len(tokenized_sep)
"""add the bos and eos tokens"""
if bos:
tokenized_str = [self.bos_id] + tokenized_str
images_seq_mask = [False] + images_seq_mask
if eos:
tokenized_str = tokenized_str + [self.eos_id]
images_seq_mask = images_seq_mask + [False]
assert len(tokenized_str) == len(
images_seq_mask), f"tokenize_with_images func: tokenized_str's length {len(tokenized_str)} is not equal to imags_seq_mask's length {len(images_seq_mask)}"
return tokenized_str, images_list, images_seq_mask, images_spatial_crop, num_image_tokens
Related #
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Learning Transferable Visual Models From Natural Language Supervision
https://github.com/openai/CLIP
https://github.com/mlfoundations/open_clip
Sigmoid Loss for Language Image Pre-Training
Qwen-VL: A Versatile Vision-Language Model for Understanding,…
Qwen2-VL: Enhancing Vision-Language Model’s Perception of the…
DeepSeek-VL: Towards Real-World Vision-Language Understanding
https://github.com/deepseek-ai/DeepSeek-VL
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for…